- (Topic 2)
You are analyzing customer purchases in a Fabric notebook by using PySpanc You have the following DataFrames: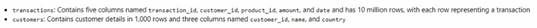
You need to join the DataFrames on the customer_id column. The solution must minimize data shuffling. You write the following code.
Which code should you run to populate the results DataFrame?
A)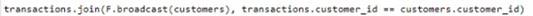
B)
C)
D)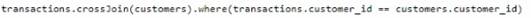
Correct Answer:
A
The correct code to populate the results DataFrame with minimal data shuffling is Option A. Using the broadcast function in PySpark is a way to minimize data movement by broadcasting the smaller DataFrame (customers) to each node in the cluster. This is ideal when one DataFrame is much smaller than the other, as in this case with customers. References = You can refer to the official Apache Spark documentation for more details on joins and the broadcast hint.
HOTSPOT - (Topic 2)
You have a Fabric tenant that contains lakehouse named Lakehousel. Lakehousel contains a Delta table with eight columns. You receive new data that contains the same eight columns and two additional columns.
You create a Spark DataFrame and assign the DataFrame to a variable named df. The DataFrame contains the new data. You need to add the new data to the Delta table to meet the following requirements:
• Keep all the existing rows.
• Ensure that all the new data is added to the table.
How should you complete the code? To answer, select the appropriate options in the answer area.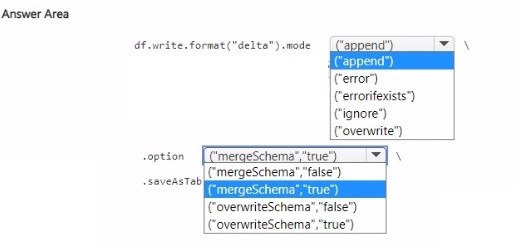
Solution:
o add new data to the Delta table while meeting the specified requirements:
✑ You should use the append mode to ensure that all new data is added to the table without affecting the existing rows.
✑ You should set the mergeSchema option to true to allow the schema of the Delta table to be updated with the new columns found in the DataFrame.
The completed code would look like this:
df.write.format("delta").mode("append") option("mergeSchema", "true") saveAsTable("Lakehouse1.TableName")
Does this meet the goal?
Correct Answer:
A
HOTSPOT - (Topic 2)
You have a Microsoft Power Bl semantic model. You plan to implement calculation groups.
You need to create a calculation item that will change the context from the selected date to month-to-date (MTD).
How should you complete the DAX expression? To answer, select the appropriate options in the answer area.
NOTE: Each correct selection is worth one point.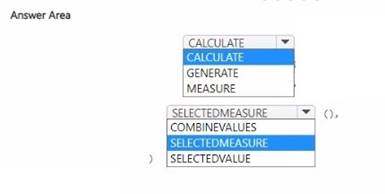
Solution:
To create a calculation item that changes the context from the selected date to month-to- date (MTD), the appropriate DAX expression involves using the CALCULATE function to alter the filter context and the DATESMTD function to specify the month-to-date context. The correct completion for the DAX expression would be:
✑ In the first dropdown, select CALCULATE.
✑ In the second dropdown, select SELECTEDMEASURE. This would create a DAX expression in the form:
CALCULATE( SELECTEDMEASURE(),
DATESMTD('Date'[DateColumn])
)
Does this meet the goal?
Correct Answer:
A
- (Topic 2)
You have a Fabric tenant that contains a Microsoft Power Bl report named Report 1. Report1 includes a Python visual. Data displayed by the visual is grouped automatically and duplicate rows are NOT displayed. You need all rows to appear in the visual. What should you do?
Correct Answer:
C
To ensure all rows appear in the Python visual within a Power BI report, option C, adding a unique field to each row, is the correct solution. This will prevent automatic grouping by unique values and allow for all instances of data to be represented in the visual. References = For more on Power BI Python visuals and how they handle data, please refer to the Power BI documentation.
HOTSPOT - (Topic 2)
You have a Fabric tenant that contains a warehouse named Warehouse1. Warehouse1 contains a fact table named FactSales that has one billion rows. You run the following T- SQL statement.
CREATE TABLE test.FactSales AS CLONE OF Dbo.FactSales;
For each of the following statements, select Yes if the statement is true. Otherwise, select No. NOTE: Each correct selection is worth one point.
Solution:
✑ A replica of dbo.Sales is created in the test schema by copying the metadata only.
- No
✑ Additional schema changes to dbo.FactSales will also apply to test.FactSales. - No
✑ Additional data changes to dbo.FactSales will also apply to test.FactSales. - Yes
The CREATE TABLE AS CLONE statement creates a copy of an existing table, including its data and any associated data structures, like indexes. Therefore, the statement does not merely copy metadata; it also copies the data. However, subsequent schema changes to the original table do not automatically propagate to the cloned table. Any data changes in the original table after the clone operation will not be reflected in the clone unless explicitly updated.
References =
✑ CREATE TABLE AS SELECT (CTAS) in SQL Data Warehouse
Does this meet the goal?
Correct Answer:
A